-from Epidemiological Bulletin,
Vol. 23 No. 3, September 2002-
Standardization: A Classic Epidemiological Method for the Comparison of Rates
Introduction
One of the fundamentals of health situation analysis (HSA) is the comparison
of basic health indicators. Among other objectives of HSA, this allows to identify
risk areas, define needs, and document inequalities in health, in two or more
populations, in subgroups of a population, or else in a single population at
different points in time. Crude rates, whether they represent mortality, morbidity
or other health events, are summary measures of the experience of populations
that facilitate this comparative analysis. However, the comparison of crude
rates can sometimes be inadequate, particularly when the population structures
are not comparable for factors such as age, sex or socioeconomic level. Indeed,
these and other factors influence the magnitude of crude rates and may distort
their interpretation in an effect called confounding (box 1).(1 ,2 ,3)
|
Box 1: Definition of Confounding
|
A confounding effect appears when the measurement of the effect
of an exposure on a risk is distorted by the relation between the exposure
and other factor(s) that also influence(s) the outcome under study.1
Similarly, a confounding factor (or confounder) must meet three criteria:
1) to be a known risk factor for the result of interest,(2) 2) to be
a factor associated with exposure but not a result of exposure(2) and
3) to be a factor that is not an intermediate variable between them.
An example is that of smoking as a counfounder in the study of
coffee consumption as risk factor for ischemic heart disease. The association
between coffee consumption and ischemic heart disease may be confounded
by smoking. Indeed, smoking is a known risk factor for ischemic heart
disease. It is associated with coffee consumption as smokers are usually
consumers of coffee, but it is not a result of drinking coffee. Smoking
is not an intermediate variable between coffee consumption and ischemic
heart disease. Schematically:

Smoking is a confounder of the association between
coffee consumption and ischemic heart disease.
Sources:
(1) Last J. A Dictionnary of Epidemiology. Fourth Edition. New York, New
York: Oxford University Press. 2001
(2) Gordis L. Epidemiology. Second Edition. Philadelphia, PA: W.B. Saunders
Company. 2000
|
The calculation of specific rates in well defined subgroups of a population
is a way of avoiding certain confounding factors. For example, specific rates
calculated by age groups are often used to examine how diseases affect people
differently depending on their age. However, although this uncovers the patterns
of health events in the population and allows for more rigorous comparison of
rates, it can sometimes be impractical to work with a large number of subgroups.(4)
Furthermore, if the subgroups consist of small populations, the specific rates
can be very imprecise. The process of standardization (or adjustment) of rates
is a classic epidemiological method that removes the confounding effect of variables
that we know — or think — differ in populations we wish to compare.
It provides an easy to use summary measure that can be useful for information
users, such as decision-makers, who prefer to use synthetic health indices in
their activities.
In practice, age is the factor that is most frequently adjusted for. Age-standardization
is particularly used in comparative mortality studies, since the age structure
has an important impact on a population’s overall mortality. For example,
in situations with levels of moderate mortality, as in the majority of the countries
of the Americas, an older population structure will always present higher crude
rates than a younger population.
There are two main standardization methods, characterized by whether the standard
used is a population distribution (direct method) or a set of specific rates
(indirect method). The two methods are presented below.
Direct method
In the direct standardization method, the rate that we would expect to find
in the populations under study if they all had the same composition according
to the variable which effect we wish to adjust or control (such as age, socioeconomic
group, or other characteristics) is calculated. We use the structure of a population
called “standard”, stratified according to the control variable, and
to which we apply the specific rates of the corresponding strata in the population
under study. We thus obtain the number of cases “expected” in each
stratum if the populations had the same composition. The adjusted or “standardized”
rate is obtained by dividing the total of expected cases by the standard population.
An example is presented in box 2.
An important step in the direct standardization method is the selection of a
standard population.(3) The value of the adjusted rate depends on the standard
population used, but to a certain extent this population can be chosen arbitrarily,
because there is no significance in the calculated value itself. Indeed adjusted
rates are products of a hypothetical calculation and do not represent the exact
values of the rates. They serve only for comparisons between groups, not as
a measure of absolute magnitude.(3) However, some aspects should be taken into
account in the selection of the standard population. The standard population
may come from the study population (sum or average for example). In this case
however, it is important to ensure that the populations do not differ in size,
since a larger population may unduly influence the adjusted rates.(5) The standard
population may also be a population without any relation to the data under study,
but in general, its distribution with regard to the adjustment factor should
not be radically different from the populations we wish to compare.
The comparative study of adjusted rates may be carried out in different ways:
we can calculate the absolute difference between the rates, their ratio, or
the percentage difference between them. Obviously, this comparison is valid
only when the same standard was used to calculate the adjusted rates. When the
national standards change (as in the United States in 1999 for example, when
a new standard was adopted based on the 2000 population instead of the 1940
standard), the time series have to be recalculated at all levels. Updating the
standard populations provides a more current common standard. For comparison
of rates from different countries, the standard population used by WHO and PAHO
is the so-called “old” standard population defined by Waterhouse.(6)
The age distribution of this population is shown in Box 3.
The direct method is most often used. However, it requires rates specific to
population strata corresponding to the variable of interest in all the populations
we wish to compare, which are sometimes not available. Even when these specific
rates are available for all the subgroups, they are sometimes calculated from
very small numbers and can be very imprecise. In this case, the indirect standardization
method is recommended.3
|
Box 2: Comparison of general age-standardized mortality
rates in Mexico and the United States,
using the direct method, 1995-1997
|
|
In this example, the standard population that was used is the so-called
“old” world standard population defined by Waterhouse (see Box
3). The crude mortality rate for all ages in the United States for 1995-1997
is 8.7 per 1,000 population. In Mexico it is much lower: 4.7 per 1,000
population. We can conjecture that the higher rate in the United States
may be due to an older population structure than in Mexico. Therefore,
we wish to study the rates of the two countries when controlling for the
effect of the age structure difference.
In this example, to use the direct method we need:
- The specific mortality rates by stratum of the characteristic we want
to control, in this case age, in each population (i.e. Mexico and the
United States)
- A standard population, stratified in the same way
First we calculate the expected number of deaths in both countries, applying
the rate of each country to the standard population (columns (4) and (5)).
The sum of all the groups gives us the total of expected deaths.
To calculate the adjusted rate, we divide this number by the total standard
population.
|
| |
|
Age-specific mortality rate
per 100,000 population, 1995-1997
|
Expected number of deaths
|
| |
Standard population
(1)
|
Mexico
(2)
|
United States
(3)
|
Mexico (4)=(1)x(2)/100,000
|
United States
(5)=(1)x(3)/100,000
|
| <1 |
2,400 |
1693.2
|
737.8
|
41
|
18
|
| 1-4 |
9,600 |
112.5
|
38.5
|
11
|
4
|
| 5-14 |
19,000 |
36.2
|
21.7
|
7
|
4
|
| 15-24 |
17,000 |
102.9
|
90.3
|
17
|
15
|
| 25-44 |
26,000 |
209.6
|
176.4
|
55
|
46
|
| 45-64 |
19,000 |
841.1
|
702.3
|
160
|
133
|
| 65+ |
7,000 |
4,967.4
|
5,062.6
|
348
|
354
|
| |
100,000 |
|
|
639
|
574
|
|
Age-adjusted mortality rate (Mexico) = 6.4 per 1,000 pop. and
Age-adjusted mortality rate (United States) = 5.7 per 1,000 pop.
When eliminating the effect of the difference in the age structure
in both countries, we obtain a rate that is higher in Mexico than in the
United States. The conclusion of the comparison of the rates is inversed
when using adjusted rates rather than crude rates.
|
|
Source of the data: Pan American Health Organization. Perfiles
de mortalidad de las comunidades hermanas fronterizas México -
Estados Unidos Edición 2000 / Mortality profiles of the Sister
Communities on the United States-Mexico border 2000 Edition. Washington,
D.C.: OPS. 2000
|
|
Box 3: “Old” Standard Populations (World
and European)
|
|
Age groups (years)
|
World
|
European
|
|
0
|
2,400
|
1,600
|
|
1-4
|
9,600
|
6,400
|
|
5-9
|
10,000
|
7,000
|
|
10-14
|
9,000
|
7,000
|
|
15-19
|
9,000
|
7,000
|
|
20-24
|
8,000
|
7,000
|
|
25-29
|
8,000
|
7,000
|
|
30-34
|
6,000
|
7,000
|
|
35-39
|
6,000
|
7,000
|
|
40-44
|
6,000
|
7,000
|
|
45-49
|
6,000
|
7,000
|
|
50-54
|
5,000
|
7,000
|
|
55-59
|
4,000
|
6,000
|
|
60-64
|
4,000
|
5,000
|
|
65-69
|
3,000
|
4,000
|
|
70-74
|
2,000
|
3,000
|
|
75-79
|
1,000
|
2,000
|
|
80-84
|
500
|
1,000
|
|
85+
|
500
|
1,000
|
| Total |
100,000
|
100,000
|
| Source: Waterhouse J. y Col. (Eds.). Cancer incidence
in five continents. Lyon, IARC, 1976. |
Indirect method
Indirect standardization is different in both method and interpretation.
An example of adjustment using the indirect method is presented in box 4. Instead
of using the structure of the standard population, we utilize its specific rates
and apply them to the populations under comparison, previously stratified by
the variable to be controlled. The total of expected cases is obtained this
way. The Standardized Mortality Ratio (SMR) is then calculated by dividing the
total of observed cases by the total of expected cases. This ratio allows to
compare each population under study to the standard population. A conclusion
can be reached by simply calculating and looking at the SMR. A SMR higher than
one (or 100 if expressed in percentage) indicates that the risk of dying in
the observed population is higher than what would be expected if it had the
same experience or risk than the standard population. On the other hand, a SMR
lower than one (or 100) indicates that the risk of dying is lower in the observed
population than expected if its distribution were the same as the reference
population. The actual adjusted rates can also be calculated using the indirect
method by multiplying the crude rate of every population by its SMR.4 Just like
in the direct method, a single value is obtained for every population which,
even though it only represents an artificial number, takes into account the
differences in the compositions of the populations.
Standardized Mortality Ratios are frequently used in epidemiology to compare
different study groups, because they are easy to calculate and also because
they provide an estimate of the relative risk between the standard population
and the population under study. However, it is important to know that there
are instances when this comparison is not adequate, like for example when the
ratios of the rates in the groups under study and in the population of reference
are not homogeneous in the different strata.(7) However, the comparison between
each group and the population of reference is always relevant. The SMRs of different
causes in a population may also be calculated using a single standard.
|
Box 4: Use of indirect standardization to compare
mortality in the Colombian department of Vichada
and mortality in Colombia in general, 1999
|
|
The crude mortality rate in Colombia in 1999 was 4.4 per 1,000 population,
with variations between 1.8 per 1,000 population in the department of
Vichada and 6.9 per 1,000 in Quindio.1 We would like to study the possible
significant differences in the observed mortality (or in the risk of dying)
in the country and in its departments. The case of the state of Vichada
is presented in this example.
In this case, in order to use the indirect method we need:
- The age-specific mortality rates by age group in Colombia
- The population of the state of Vichada stratified by age
- The total number of deaths observed in the department of Vichada
The first step is to calculate the expected number of deaths in Vichada
by applying the standard rates to the population of the department (column
(3) = (1) x (2)). Then the calculated deaths are summed up and the SMR
is calculated by dividing the total number of observed deaths by the expected
deaths.
|
| |
Tasas de mortalidad específica
por grupos de edad, Colombia, 1999 (i)
(1)
|
Población del departamento
de Vichada (i)
(2)
|
Muertes observadas en Vichada
(3)
|
Muertes esperadas en Vichada,
1999 (i)
|
|
0-4
|
339
|
11,392
|
61
|
39
|
|
5-14
|
34
|
21,930
|
5
|
7
|
|
15-44
|
219
|
38,244
|
27
|
84
|
|
45-64
|
752
|
7,083
|
22
|
53
|
|
65 +
|
4.573
|
1,839
|
27
|
84
|
| |
|
80,488
|
142
|
267
|
|
SMR for Vichada = 53%
The SMR of 53% indicates that in the population of Vichada the risk
of dying is 47% less than expected according to the mortality standards
of all of Colombia, controlling for the age variable
|
|
Fuente de los datos:
(i) Situaci�n de Salud en Colombia. Indicadores Básicos 2002. 2002 [Folleto
producido por el Ministerio de Salud de Colombia y la Representaci�n OPS/OMS
en Colombia]
|
|
NOTE: Confidence interval for SMRs
The confidence interval provides the range of values within which we expect
to find the real value of the indicator under study, with a given probability.
That way, it gives an estimate of the potential difference between what
is observed and what is really happening in the population, which helps
in interpreting the value of the observed indicator. The 95% confidence
interval is the most used. As mentioned previously, it indicates the range
of values within which we expect to find the real value of the indicator,
with a probability of 95%.
In the case of the SMR, the calculation of the confidence interval can
be carried out in the following way:
1) First, the Standard Error (SE) for the SMR is calculated using the
following formula:

2) The 95% Confidence Interval (CI) is calculated as follows: 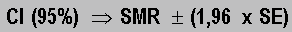
where 1.96 is the value of the Z distribution with a level of confidence
of 95%. It is assumed that the values follow a normal distribution.
|
|
In this example: SE(Vichada) = 4.4 and CI(Vichada) (95%) = [44.4 ;
61.6]
The confidence interval indicates that we know with a probability of 95%
that the SMR’s value is between 44.4 and 61.6.
|
Conclusion
As with any summary measure, adjusted rates may hide great differences between
groups, which can be of importance to explain changes in the rates due to or
associated with the variable that we wish to adjust for, for example. Nevertheless,
whenever possible it is important to analyze the specific rates along with the
adjusted rates. The two methods used in a single population should lead to the
same conclusions. If it were not the case, the situation in the different population
strata requires more in-depth research.(4)
One of the reasons for sometimes limited use of these methods is the lack of
tools or instruments that simplify it. To respond to this need, the General
Direction of Public Health of the Xunta de Galicia and PAHO’s Special Program
for Health Analysis have developed the “EpiDat” computer package for
analysis of tabulated data. EpiDat is distributed free of charge via the Internet
at: http://www1.paho.org/Spanish/SHA/epidat.htm.
A newer version of this package will be issued soon. The software SIGEpi (see
http://www1.paho.org/English/sha/be_v22n3-SIGEpi.htm),
which combines the capacity of a geographic information system with epidemiological
tools, also allows to generate adjusted rates.
In short, adjusted rates allow for more exact comparisons between populations.
This is important because it can be used in setting priorities between groups.
Nevertheless, the crude rates are the only indicators of the real dimension
or magnitude of a problem and hence remain valuable public health tools.
References:
(1) Last J. A Dictionary of Epidemiology, Fourth Edition. New York, New York:
Oxford University Press. 2001
(2) Jenicek M, Cléroux R. Epidemiología: Principios, Técnicas
y Aplicaciones. Barcelona, España: Salvat Editores. 1987
(3) Gordis L. Epidemiology. Philadelphia, PA: W.B. Saunders Company. 1996
(4) Pagano M, Gauvreau K. Principles of Biostatistics. Belmont, California:
Wadsworth, Inc. 1993
(5) Kramer S. Clinical Epidemiology and Biostatistics. A primer for Clinical
Investigators and Decision-makers. Berlin Heidelberg, German: Springer-Verlag.
1988
(6) Waterhouse J et al. (eds.). Cancer incidence in five continents, Lyon, IARC,
1976.
(7) Szklo M, Nieto J. Epidemiology, Beyond the basics. Gaithersburg, MD: Aspen
Publishers, Inc. 2000
(8) Xunta de Galicia, Consellería de Sanidade e Servicios Sociais. Pan
American Health Organization, Special Program for Health Analysis. Análisis
Epidemiológico de Datos Tabulados (Epidat), Version 2.1 [Computer software
for Windows]; 1998
Source: Prepared by the Analysis Group of PAHO’s Special
Program for Health Analysis (SHA)
Return to Index
Epidemiological Bulletin, Vol. 23 No. 3, September
2002